
For decades, the Computer History Museum (CHM) has worked to collect, document, and interpret the history of artificial intelligence (AI). It has collected objects, archives, and software and produced oral histories. CHM has convened vital conversations about AI in its public programs, examined the history and present of AI from multiple perspectives in our blog and publications, and interpreted the story of AI and robotics to our visitors onsite and online in our permanent exhibition, Revolution: The First 2,000 Years of Computing.
With the rise of new AI technologies typically called “machine learning” or “deep learning” based on neural networks and large data sets, and the facility of these technologies in areas such as speech and visual recognition tasks, CHM staff have followed efforts by some of the largest museums internationally to use and explore these new tools. Concurrently, CHM has been sharpening ideas about and commitment to a new goal that we call “OpenCHM.” Its core strategy is to harness new computing technologies to help us make our collections, exhibits, programs, and other offerings more accessible, especially to a remote, global audience.
Our commitment to OpenCHM led us to join the new community of museums and other cultural institutions experimenting with AI, in service to our broader purpose of accessibility. We determined that such an AI experiment could help us learn how we should, or should not, design AI tools into our larger OpenCHM initiative. Further, we believed that given the culture of sharing and collaboration in the museum, libraries, and archives sector, an AI experiment by CHM could benefit the community at large. It is in that spirit that we here offer our experiences and lessons learned.
![]()
For our AI experiment, CHM was gratified to receive a grant (Grant MC-245791-OMS-20) from the Institute of Museum and Library Services (IMLS; www.imls.gov), an agency of the US federal government created in 1996. In recognition that museums and libraries are crucial national assets, the IMLS gives grants, conducts research, and develops public policy. Of course, the views, findings, and conclusions or recommendations expressed in this essay do not necessarily reflect those of the IMLS.
CHM’s grant was part of the IMLS’s National Leadership Grants for Museums and supported a one-year, rapid-prototype project to create a simple search portal for a selection of digitized materials from CHM’s collections—especially video-recorded oral histories—and the metadata about them generated by commercial machine learning services. Our thought was that by having internal staff and external user evaluations of this portal, we could assess the present utility and near-future potential of the various machine learning tools for ourselves and the community as well as gain first-hand experience with the actual use of these tools in practice.
![]()
This project was also supported in part by the Gordon and Betty Moore Foundation (moore.org). The Gordon and Betty Moore Foundation fosters path-breaking scientific discovery, environmental conservation, patient care improvements and preservation of the special character of the Bay Area.
For our experiment, we chose to use Microsoft’s commercial machine learning services, currently marketed as “Cognitive Services.” Our reasons were several. Microsoft is supporting CHM with technology, including generous use of their cloud computing services (Azure) and productivity software as well as donations of hardware. Microsoft’s market-competitive Cognitive Services are part of their Azure cloud computing offerings. With our existing use of Azure, evaluating Microsoft’s Cognitive Services tools made good sense to us particularly, and their overall standing in the machine learning services market made sense for the broader museum community.
The project lead for CHM’s AI experiment was our Chief Technology Officer, and our IMLS grant was for $50,000, with CHM contributing an additional $15,000 of staff time. Of this, $30,000 was devoted to an external technology development firm and other technology costs. CHM applied an additional $20,000 from the Gordon and Betty Moore Foundation to development costs. Additionally, CHM used some of its donated allocation of Azure services to cover the cost of some of the cloud computing services (storage, database, indexing, web applications) and of using the Cognitive Services tools. With the difficulties of the pandemic, and the work itself (including evaluation and communication), we requested and received a six-month extension to our original one-year workplan.
One of our first tasks for the project was to select a corpus of materials from our collections to use for the experiment. We devoted considerable effort to this selection, choosing oral histories for which we had both video recordings and edited transcripts. Further, we chose oral histories that grouped into two topic areas—the history of Xerox PARC and the history of artificial intelligence—as well as a selection chosen for a diversity of gender, race, sexual orientation, and language accent. Additional audio recordings, scanned documents, and still images were chosen to add to the corpus that connected to these topic areas.
In the end, our selection process turned out to have been more subtle and nuanced than necessary. In this rapid prototype project, we were not able to take full advantage of our selections for topics or for diversity because the prototype did not offer that level of sophisticated use. We would have been better served by selecting a corpus more quickly, based primarily on representing the kinds of digital file types, sizes, and qualities held in our collections: a more technical than intellectual selection.
Our other initial task was to design our prototype portal, describing what we wanted to achieve so that it could be translated into a set of requirements for our external developer. The vision for the portal that we designed focused on:
While this vision was translated into a set of requirements that our development contractor pursued, later we found that our process left important elements unacknowledged. For example, team members assumed that the existing metadata about the items in the corpus from our existing collections database would be attached to the items in the rapid prototype, along with the Cognitive Services generated metadata. By the time that we realized that we had not imported that data into the prototype, doing so would have required a cost-prohibitive reworking of the prototype’s database. In another instance, team members assumed that the prototype portal would have search features common to many commercial websites like YouTube or a Microsoft service built on Cognitive Services called Video Indexer. It did not, because those had not been explicitly articulated in the requirements setting.
Across the development of the rapid prototype portal, and the migration of our corpus into its data store, most of the work of the effort was in communication. Despite significant efforts and strong intentions, our team encountered difficulties in communicating across our own collections and IT groups, translating our goals and concerns into the idioms and workflows of the other. This is a well-known issue in the world of libraries and museums, perhaps one for which teams should explicitly plan, building in touchpoints, correction strategies, and most of all adequate time for meeting, discussion, and resolution. These issues were only compounded by the need to also work with our external developer firm. Here again were the same issues of translating across idioms, workflows, and organizational structures.
One benefit of these difficulties was that we needed to develop an approach, and workflow around evaluation early in the process to gauge the progress of the prototype development. This evaluation work evolved into our more formal efforts for internal and external evaluation once the prototype was deemed ready. Having a data scientist on our staff involved in the project from an early stage proved to be an important asset. Our experience supports the general best practice of involving evaluators in a project from the very beginning.
Our final phase of development of the rapid prototype was actually one of simplification. We chose to strip out features that were not yet adequately developed so that they would not become distractions in our evaluation work. In this, we focused on the primary goal of the project and the evaluation: To judge the current utility and near-term promise of using commercial machine learning tools for expanding access to our collection. Features that were not critical to assessing how machine generated metadata might serve this goal were stripped out.
One feature that could have been significant to this core assessment goal was removed: the networked graph view presenting metadata relationships between items returned by a search query. Despite some significant development of this feature, our budget of time and expense was inadequate to develop this promising avenue successfully. We remain convinced that such a view of search results and their interconnections could be a vital discovery and access tool, but it proved beyond the reach of our experiment.
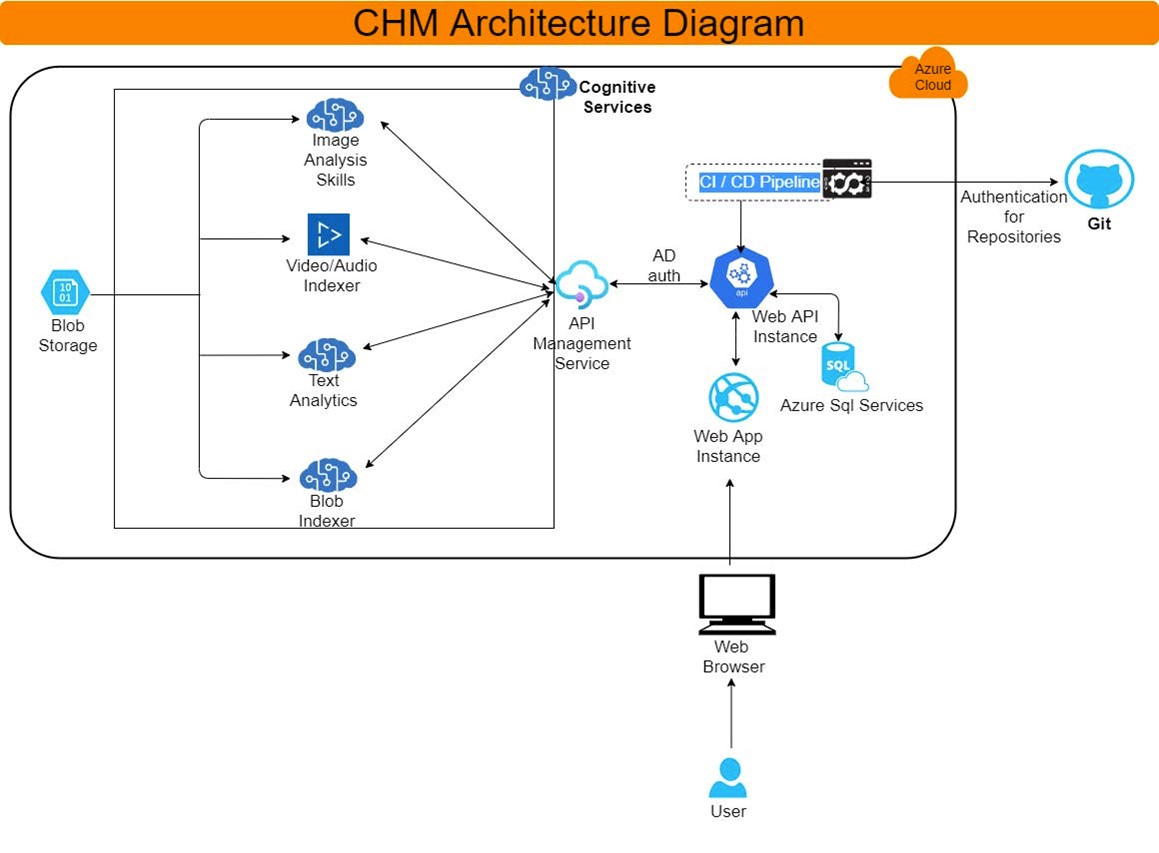
An outline of the technical architecture of the prototype, from a design document.
The prototype portal gives users an interface to use Azure Cognitive Search to query an Azure SQL database. The database contains metadata about each of the collection items in the corpus, which are themselves held in an Azure storage container. A search query results in the display of the result items, divided by item type (video, document, audio, or image). When an individual item is selected for view, the machine-created metadata for that item is available to see and, in some cases, allows for navigating to the relevant position in the item.
For audio and video files, Video Indexer from Microsoft’s Cognitive Services was applied. The tool creates an automatic transcript of the recording, which our system treats as a metadata field. Video Indexer further extracts metadata from the transcript: keywords, topics, and people. Our system treats each of these as additional metadata fields in the database. Lastly, Video Indexer analyzes the audio to produce sentiment data, and the video to generate faces data. Our system treats each of these as metadata fields. For document files, in our case PDFs, we applied Text Analytics from Cognitive Services. From the text, the following metadata was extracted: key phrases, organizations, people, and locations. Occasionally, document files were mistakenly processed as static images, producing the metadata: image text, image tags, and image captions. These same metadata were produced for our properly processed static images.
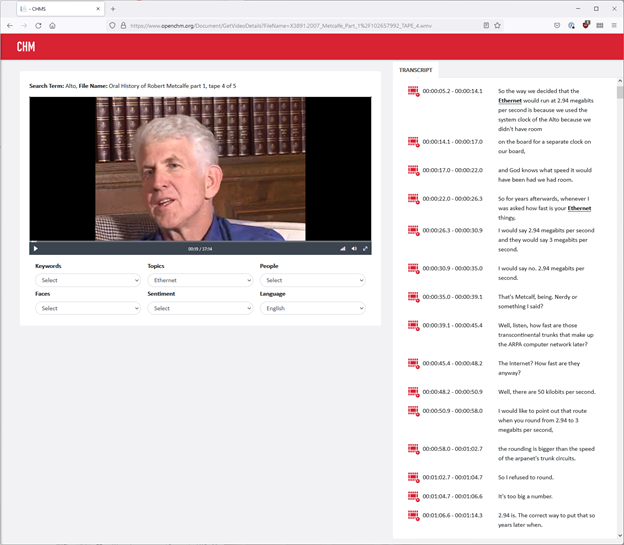
A screenshot of the prototype, displaying the oral history recording of networking pioneer Bob Metcalfe. The automatic transcription, matched and timecoded to the video playback, appears at the right. The topic metadata “Ethernet” has been selected, resulting in the highlighting of the term in the transcription.
Here, the transcription has been automatically translated into Chinese.
For our evaluation, we created surveys for both internal and external users and shared web access to the prototype portal. Because our focus was on our oral history collection, the prototype was geared toward adult professional users and academic researchers, as was our evaluation. Our internal users were staff from a variety of groups: collections and exhibitions; marketing and communications; education; and information technology. Our external users were historians as well as a variety of library, museum, and archive professionals.
In their evaluation of the current utility of the machine learning generated metadata about the collection items, our external evaluators were notably more positive than were our internal evaluators. For the video items, almost all of the external users found the extracted keyword and topic metadata from the automatic transcriptions to be useful, while much less than half of the internal users agreed with them. This same divergence held for document items, where every external user found the extracted person metadata to be useful, while only about half of internal users did.
Beyond person metadata, about half of external and internal users found the key phrases, organizations, and locations metadata useful, although internal support was consistently lower. For audio items, this same pattern held. Roughly half of internal and external users found the keywords, topics, and people metadata useful, with internal uses slightly but consistently lower.
Our working explanation for the lukewarm assessment of utility across the board, and the higher external judgement of utility, is that users believe that the machine generated metadata—the automatic transcripts, and the summary data extracted from them—are better than no metadata, and that external users feel more strongly that anything that allows expanded access to the collection has value.
Internal users, many of whom are closer to the human curation and production of metadata about the collection, are clearly more critical of the machine results. However, there were cases where there was unanimity among our internal and external evaluations. Almost every evaluator found that the descriptive tags and captions for still images, and the sentiment metadata for video and audio files were not particularly useful, while almost every evaluator judged the automatic transcriptions of video and audio items to be useful.
This image shows the automatic translation of a PDF of the transcription of graphics pioneer Alvy Ray Smith’s oral history into Hindi.
From the perspective of our collections group, the lessons learned from this rapid prototype for our OpenCHM goals are clear, direct, and very helpful. Automatic transcription of video and audio materials using machine learning tools will be our top priority in this area, followed by automatic translations of these transcripts into a set of languages. In the prototype project, we used Microsoft’s Cognitive Services “out of the box” functionality, without any customization or training. For our future efforts in automatic transcription and translation, we will strongly pursue customization of the machine learning tools by using available options to train them on our own corpus of documents and human-produced transcripts. Lastly, we will ensure that future systems allow the user to select between human or machine generated metadata, or a combination of the two. In all cases, machine generated metadata will need to be clearly identifiable.
From the perspective of our information technology group, the prototype project has also generated clear and useful lessons about process that should inform upcoming work on OpenCHM. The need to define, document, and agree upon all the requirements carefully is clear. In working with new technology, the goals and outcomes should be simplified and clearly defined. Developing an effective process for exploring the use of new technology, and learning clear lessons from this, is essential because new tools and capabilities are being constantly developed.
From my own perspective, the rapid prototype project was an extremely valuable experiment for CHM, and I hope for the larger community. We have a much greater understanding of the realities of using current commercial machine learning services in a museum setting and the limitations. Below is what I have learned as an historian and curator from working on the project and from analyzing the prototype that we have built.
The machine-generated metadata do not, at this stage, provide much beyond that which is available through standard full-text search. This is true both for the expert and the casual user. Little of the machine-generated metadata offer insights beyond full-text search: The systems cannot readily identify anything not explicitly in the text itself. This includes person, key phrases, organizations, and locations metadata for documents, and keywords, topics, and people metadata for audio and video. That said, these metadata do serve as previews of the full text and are useful as a kind of browsing of the full text. An important exception to the limitation to the full text was found in the case of prominent individuals. The systems were able to associate the names of prominent individuals with topics not explicitly contained in the full text. For example, the system was able to associate the names “Steve Jobs” and “Gordon Bell” with the topic of “National Medal of Technology and Innovation,” and the name “Nandan Nilekani” with the topic “Chairman of Infosys.” Sentiment metadata is not useful, as it is mostly inaccurate for the videos in our sample.
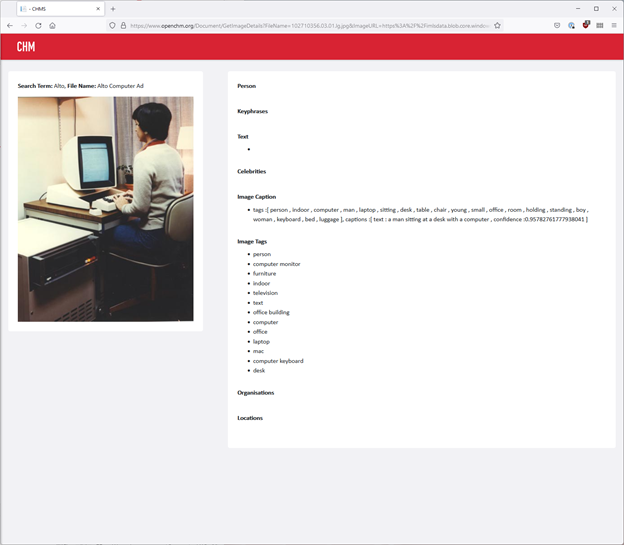
The metadata produced by the prototype for a photograph of a person using a Xerox Alto computer.
For the purely visual items in our prototype, our 2D still images, the system did, of course, provide metadata largely unrelated to text. When text did appear in an image, the system did a very good job at identifying it and providing the recognized text as metadata. Image recognition provided metadata about the scene that was in the main too general for productive use as alternate text for screen readers and also noisy with false tags, likely due to the specialized content of the images in our collection.
Throughout the project, it became apparent that the commercial machine learning services are primarily geared toward the needs of commercial customers, for uses in marketing, customer management, call centers, etc. They are tuned to the analysis of relatively short pieces of video, audio, and text, and to results fitted to commercial interactions. Our experience shows that the needs for interactions in the museum space—where accessing, assessing, and using information is paramount—require that machine learning services be appropriate for contending with larger video, audio, text, and image files, and have much more stringent requirements for accuracy, thoroughness, and overall quality. We hope that future experiments with using machine learning tools customized through training on our collection can address these stringent quality requirements.
From our experience, I believe an important lesson is to decouple a museum’s database from any specific machine learning service. Instead of directly tying the database to particular commercial AI services through APIs or other links, one should make space for the results of machine learning services to be imported into the museum’s database. Digital elements from, or representations of, the museum’s collection could be processed by the services, and the data so produced could then be placed in the database. This would be a batch process, rather than a live link. That is, one should create fields in the museum’s database where the results of changing or different machine learning services can be placed, and later replaced, much like human-curated metadata—like descriptions—are refined and corrected over time.
The greatest promise for machine learning that I see currently from my experience with the prototype is for automatic transcription of audio and video items. These automatic transcriptions have a workable accuracy for the purpose of discoverability and improving search. They provide useful full texts for audio and video materials. They really could unlock vast parts of the collection. Similarly, cutting-edge text recognition of scanned documents would be terrifically important to unlocking other huge swaths of the collection as they are digitized.
In the analysis of 2D images, the greatest potential for the machine learning services that I could see were in providing alternate text for images for accessibility for people with vision challenges. I also think that text recognition in 2D images and moving images is useful, providing more metadata text for full-text search.
Lastly, automatic translation of museum materials, including metadata, does seem to hold promise for making the museum and the collection more accessible to speakers of languages other than English. Perhaps we could use automatic translation tools to create versions of the museum metadata in a set of languages and give users the ability to operate in a language version of their choice. In this way, both the searches and the metadata would be in the language of the user’s choice. Perhaps as automatic translation becomes cheaper, more versions could be offered. As automatic translation improves, new language versions of the metadata could be created.
Machine learning tools appear to have their proper place in the toolkits of museum professionals. Used properly, machine learning tools can augment the skills and knowledge of museum staff, assisting them in unlocking, sharing, studying, and caring for the collections with which they work.
If you’re a museum professional, or simply fascinated by machine learning and want to hear more about our experience, join us on February 18 at 11 am PT. Register here.