
If you’ve heard about digital preservation in the news, chances are it was a story about loss or potential loss. For almost 20 years now, we’ve been warned that we could be facing a “digital dark age, ” meaning that very little of what we create using computers will be preserved for future generations.1 The challenges facing digital preservation are real, but all too often these warnings have not been paired with examples of what people in the field have been doing to face them.
In this post, I’m going to talk about some of the steps the Computer History Museum (CHM) has taken in recent years to ensure that it will be able to preserve its already substantial and growing digital collections, focusing specifically on the Museum’s new digital repository.
First, a bit of background. The Museum’s digital collections fall roughly into three categories:
1.Donations of material in already digital formats
This includes both software (applications, code, etc.) and data (word processing documents, image files, and so on). Much of it is stored on older physical media (tape, cartridge, floppy disk, etc.) that needs to be read with specialized equipment; although, we are increasingly seeing donations arrive in the form of files on modern hard drives or downloads from shared cloud storage folders.
2.Digital copies made from physical items
These range from image scans of photographs and paper documents to audio and video files created through digitizing items from our audiovisual collection.
3.Museum-created digital content
The Museum records all of its oral histories and live programs, along with some special events such as the Fellow Awards and Exponential Center launch. The oldest recordings are on tape formats, but for many years now this production process has been entirely digital. Video is recorded onto cards in cameras and then copied onto hard drives for editing. There is no longer a one-to-one correspondence between a given piece of physical storage media and a segment of video.
This third category has been one of the main drivers behind the Museum’s push to build a more robust digital storage and preservation infrastructure. With the adoption of high-definition standards, the volume of in-house video added to the Permanent Collection has grown rapidly in recent years, from just over 5 TB in 2011 to over 10 TB each year from 2013–2015, to over 15 TB in 2016. As 4k video becomes more common, this volume is only going to increase.
By 2011, it became clear that the Museum’s existing storage infrastructure, already straining to keep up with the then much smaller digital collection, was in need of an upgrade. That year, with the aid of a grant from Google.org, the Museum began work on building a digital repository. After extensive preparation and testing, we officially, albeit quietly, launched the repository in April 2015.

Signage outside one of the server rooms where the digital repository is stored.
The purpose of the repository is to provide stable, redundant, long-term storage for all of the Museum’s digital collections. Although the repository is not exactly a place, it can be seen as analogous to the facilities that the Museum uses to store its physical collection. And just as the Museum has had to develop procedures for managing the physical collection, similar procedures needed to be developed to facilitate the ingest, retrieval, and monitoring of the digital collection.
Indeed, it would be a mistake to look at the repository storage system alone as fulfilling the needs of preservation. Rather, it’s the combination of the storage system and the processes we’ve put in place to bring material into the repository so that we can continue to access it that makes up the core of the Museum’s digital preservation system. I briefly describe both below.
After evaluating a range of options, the Museum decided to build and manage its own storage infrastructure. Without getting into too much technical detail, the repository consists of three servers, all of which are RAID setups using ZFS for the file system and Ubuntu as the operating system. One server operates as the main server, with the other two operating as mirrors. The servers are physically separate, with one located offsite. Additionally, all data is backed up to LTO tape on an incremental basis, with full backups made every six months.
There are many benefits to this design:
In some ways, the digital repository is purely data storage: We could send virtually any type of data to it, in almost any arrangement, and the system would replicate it, monitor it, and back it up to tape. But, of course, the requirements of managing a digital collection are higher than that. At the risk of stating the obvious, at a minimum we need to be able to track each item we’ve sent to the repository, check if it is still there, and easily retrieve a copy of it when needed.
This is where another application comes in: Archivematica. Archivematica is open-source digital preservation software designed for libraries, archives, and museums. Archivematica is not itself a storage system, but is meant to be used in combination with a storage system. As we’ve implemented it, Archivematica acts as a sort of additional layer on top of the digital repository.
We use Archivematica to:
To sum up, everything added to the digital collection is:
By continuing to rely on Mimsy as the central cataloging system, we have been able to avoid needing to maintain two separate cataloging systems, one for physical material and one for digital. This also makes it possible to ingest material into the repository sooner rather than later, as items do not need to be fully cataloged and described before they can be ingested.
In the 18 months that the repository has been in production, we have been able to ingest over 40 TB of material, most of it video. There is still quite a lot of work to do to migrate our existing collections from legacy storage into the new system but we are well underway. And with this baseline of bit-level preservation established we are able to commit more time to working on some of the more complex challenges of digital preservation, such as how to maintain the ability to render file formats in the future and how to preserve and execute old software, topics that will be the subject of future blog posts.
Can we guarantee that this repository infrastructure will last forever? To be honest, forever is a long time and technology changes rapidly enough that it’s hard to believe that the Museum will be running the same infrastructure, just with newer hardware, in 20 or possibly even 10 years. But what we can say is this: As long as the Museum exists, it will be committed to preserving the digital collection, whatever the form that preservation infrastructure will take.
Since all of that may still seem a bit abstract, I want to end with two concrete examples from the Museum’s moving image collection. The first are the videos from the 1986 ACM Conference on the History of Personal Workstations, which we posted online earlier this year. Almost all of these videos exist in the Museum’s collection only in the form of U-matic tapes. U-matics were a once common format that is still readable today with the right equipment.
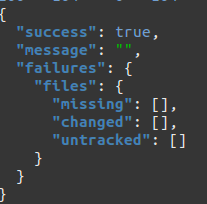
A machine’s eye view of a successful check of a package.
The Museum, however, has not been able to read U-matics in-house for some years, and as a result sent the tapes to the Bay Area Video Coalition to be digitized. Until the digitization was completed, there was no way of knowing whether the videos would be playable. But now that they have been digitized, they are readily available for use and re-use. There is also a very real chance that the content of these tapes, as video files, will be preserved and remain readable for longer than the physical tapes themselves, which depend on the continued availability of U-matic playback equipment. Finally, because the files are in the repository, we can check on the package at any given time to make sure that it remains complete.
The second example I want to highlight is from CHM’s Revolution exhibition. The Museum shot a large amount of video for use in the exhibit, only a fraction of which made it into the final videos that you can see in person or online. For example, in the gallery for Computer Graphics, Music, and Art, you can watch about three minutes of Max Mathews, one of the most influential figures in the history of computer music, demonstrate his radio baton. This video shows just a portion of a longer demonstration, which you can watch below or on our YouTube channel.
This video exists only in digital form. Shot in HD in 2010, it was never recorded onto a physical tape. It has been accessioned into the collection, cataloged, and ingested into the digital repository, thus ensuring that people will be able to find and view it in the future, whether or not YouTube continues to exist.
That, I think, is the ultimate value of having the repository: not preservation just for preservation’s sake, but for the sake of being able to provide continuing access into the future.
Building, and now maintaining, the repository has truly been a team effort. I’d like to thank everyone on the digital repository team for their hard work: Paula Jabloner, Al Kossow, Edward Lau, Ton Luong, German Mosquera, and Vinh Quach.
Notes