
Access the Xerox PARC file system archive here.
“Is my phone really backed up in the Cloud?” “When was the last time I backed up my laptop?” “Is it true that I need a local backup of my Google Drive?!” “Oh dear, I forgot my password!” Now that we have interwoven computers so deeply into our daily lives, an ancient anxiety has become a fiercer everyday companion for us. For centuries we have worried “Are my most precious records okay?” In the past, we calmed this anxiety using a variety of technologies: safety deposit boxes, shoe boxes, photo albums, photocopies, scriptoria, institutional archives, and more. In a world of digital computing, we are all too aware of the fragility of record keeping. In some ways, our ancient anxiety has expanded.

Scriptoria were dedicated spaces for the copying of manuscripts, making this a drawing of a 16th century backup. From the National Gallery of Art. https://www.nga.gov/collection/art-object-page.74850.html
Computing professionals have been living with this digital flavor of archival anxiety for longer than the rest of us. From the very beginning, the fluidity and fungibility of digital information came with fragility. Making matters worse, many of the means for holding and storing digital information were less reliable and much harder to work with than today’s. As a result, computing professionals met their anxiety about—and real challenges of—digital fragility with a new discipline: They started to make purposeful copies. They began to back things up.

PARC in 2022. Cmichel67, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
In 1970, the well-heeled corporate behemoth Xerox, with a nearly perfect monopoly on the quintessential office technology of photocopying, cut the ribbon on a new and ambitious bet on its future: the Xerox Palo Alto Research Center (PARC). PARC was a large research and development organization, comprised of distinct laboratories. Several concentrated on extending Xerox’s dominance of photocopying, like the General Science and Optical Science Laboratories. Others, specifically the Computer Science and Systems Science Laboratories, were aimed at a new goal. They would develop computer hardware and software that could plausibly form the basis for the “office of the future” some ten to fifteen years hence, giving Xerox a profound head start in this arena. The previous year, Xerox had leapt into the computer industry through the purchase, for an enormous sum, of the company SDS.
The leadership of PARC scoured the computing community across the United States and recruited what proved to be an astonishing collection of young talent. Part of the attraction PARC held for this cohort was, surely, the fact that the new laboratories held the opportunity to pursue a vision about the future of computing that they already held deeply. In this future, computing would be increasingly personal, graphical, interactive, and networked. Xerox’s deep pockets, and a PARC leadership that shared this vision, proved compelling.

The MAXC computer at Xerox PARC. http://bitsavers.trailing-edge.com/pdf/xerox/maxc/Pictures/Maxc.jpg
At PARC, the new recruits wanted to have the same sort of computing environment they had been familiar with in their academic research: a PDP-10 mainframe from the Digital Equipment Corporation running the timesharing TENEX operating system from BBN. Xerox refused. They had just purchased SDS, a maker of timesharing computers, and couldn’t countenance such a major purchase from their prime competitor. The PARC computing crowd responded by simply building their own clone of a PDP-10, calling it MAXC (an eye-poking pun on the name of the founder of SDS, Max Palevsky), and installed TENEX. Immediately, they began to back up what they were creating with MAXC. Using a TENEX program named BSYS, the PARC researchers could store their data and programs on 9-track magnetic tapes. Tape backups had arrived at PARC.

A 9-track tape drive in the collection of the Computer History Museum. https://www.computerhistory.org/collections/catalog/102752062
The next several years to 1975 contained a remarkable flourishing of computing developments at PARC. The researchers created the Alto computer and a swath of novel software for it that, through the subsequent decades, has broadly defined our use of computers. To learn more about this remarkable story, you might start here. Critical to the use and success of the Alto were PARC’s innovations in computer networking, specifically the creation of Ethernet for wired connectivity. Ethernet wove the many Altos across PARC together, further connecting them to the now two MAXC systems as well as a variety of printers. Moreover, PARC researchers developed the PUP networking protocol, allowing Xerox to knit together many local Ethernet networks across the US into a sprawling corporate internetwork.

The Alto computer. https://www.computerhistory.org/collections/catalog/102710353
Individual Alto users could store and back up their files in several ways. Altos could store information on removable “disk packs” the size of a medium pizza. Through the Ethernet, they could also store information on a series of IFSs, “Interim File Servers.” These were Altos outfitted with larger hard drives, running software that turned them into data stores. The researchers who developed the IFS software never anticipated that their “interim” systems would be used for some fifteen years.
With the IFSs, PARC researchers could store and share copies of their innovations, but the ancient anxiety demanded the question: “But what if something happened to an IFS?!” Here again, Ethernet held a solution. The PARC researchers created a new tape backup system, this time controlled by an Alto. Now, using Ethernet connections, files from the MAXC, the IFSs, and individuals’ Altos could be backed up to 9-track magnetic tapes. Later, at the end of the 1970s, the PARC researchers even developed a new program called ARCHIVIST, which ran on a more powerful successor to the Alto known as the Dorado. ARCHIVIST automated the process, allowing researchers to archive to and retrieve files from the IFSs by sending simple commands through electronic mail.
Nearly a decade later, at the close of the 1980s, PARC’s researchers increasingly adopted commercially produced computers from outside the company, rather than the Altos, Dorados, and other systems that they had devised in-house. These outside computers were new workstations produced by a local firm, Sun Microsystems. While the Sun systems were directly inspired by the Altos, they brought PARC closer to the computing mainstream through Sun’s embrace of the Unix operating system and microprocessors. This shift to Sun implied yet another wrinkle for PARC’s solutions to its archival anxieties.

A Sun workstation in a Stanford laboratory. https://www.computerhistory.org/collections/catalog/102657163
By the start of the 1990s, PARC’s computer researchers began storing their information on new Unix-based servers using Sun’s Network File System (NFS) protocol, which has gone on to be a standard for Unix and Linux systems worldwide. These new PARC NFS servers used 8mm digital tape cassettes for backup. MAXC was decommissioned, and no one used the ARCHIVIST system anymore. PARC had accumulated an impressive thicket of 9-track magnetic tapes holding backups of programs, data, messages, and documents from the astonishing contributions of PARC to computing across the 1970s and 1980s, but now no one was using the 9-track tape systems anymore. With this, a particularly horrible aspect of the ancient archival anxiety came to the fore: “What if I lose the key to my lock box?” “What if I can’t access my backups anymore?” Now backup’s twin, migration, took center stage. PARC’s computer crowd wrote fresh programs that migrated the data from the 9-track tapes to the new 8mm digital tape cartridges, which they also used for their NFS servers. The older tapes were discarded, and the 8mm tapes of this remarkable record of the work of the 1970s and 1980s then sat for another decade.

An 8mm data tape cartridge. Mister rf, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
Like hope, migration springs eternal. In 2003, the researchers at PARC realized that, while 8mm tapes were still in use, other media were becoming more popular. To keep the archive of PARC’s astonishing accomplishments accessible, migration would again be necessary. In that year, PARC researcher Dan Swinehart approached Al Kossow to tackle the challenge. Kossow was then a senior engineer at Apple Computer and already known as a passionate preservationist of both computer hardware and software, especially around the Alto. Kossow was able to transfer all the data from the 8mm tapes to a set of DVD-ROM discs. Again, this unique archive for the history of computing was safe, sound, and accessible—strictly within the confines of PARC.

Al Kossow in his CHM laboratory. https://computerhistory.org/blog/restoring-yesterdays-computer-system-of-tomorrow-a-conversation-with-curator-alto-restorer-al-kossow/
A few years later, in 2006, Kossow joined the Computer History Museum (CHM) full-time as the Robert N. Miner Software Curator. When he had worked on the migration of the PARC archive to DVD, Kossow had created an extra CD-ROM onto which he had copied almost 15,000 files relating to the work done specifically on the Alto in the 1970s and 1980s, reflecting his keen appreciation for the importance of the Alto in the history of computing. Now at CHM, he and others began an effort to see if PARC would be willing to donate the extra Alto CD-ROM to CHM, and thereby open it up to the world. Testifying to the perseverance of CHM and the sagacity of PARC, the Alto archive CD-ROM was donated to CHM in 2011 with permission to make it public.
CHM now faced a major challenge. How could this nearly four-decade old software, data, and information be made accessible to today’s public? The information was created with a now deeply obsolete forty-year-old experimental computer, with research software that no one had touched in decades. Much of the Alto archive was in now arcane formats for printing like “Press” or for document editing like “Bravo.” Certainly, you couldn’t provide the public with working Altos to read the archive.

Paul McJones (right) in 1973, with Edsger Dijkstra. https://mcjones.org/dustydecks/archives/2011/04/
An answer to the dilemma came in 2013, through the contributions of Paul McJones. McJones is a retired software engineer and established software preservationist who had met many (future) PARC researchers while he was working at Berkeley in the 1960s and 1970s. In the second half of the 1970s, McJones had done programming for the new division set up by Xerox to commercialize PARC’s computer innovations. He again worked with many former PARC researchers in projects at DEC’s laboratory in Palo Alto, and then again as a principal scientist at Adobe.
During 2013, McJones crafted a program that processed the Alto archive, creating HTML translations of Bravo files and PDF translations of Press files, and organizing them into a set of web pages for access, search, and browsing. With this further act of migration qua translation, the Alto archive was at last ready to share with the world, and in 2014 https://xeroxalto.computerhistory.org/ went live.
Since its launch, the Alto archive has proved essential for efforts at both CHM and the Living Computer Museum (LCM) in Seattle. At LCM (which sadly closed during the COVID pandemic), senior software engineer Josh Dersch used the archive and Al Kossow’s Bitsavers repository to build ContrAlto, an emulator for the Xerox Alto that can run on contemporary computers and, in turn, run the software found in the Alto archive. At LCM, ContrAlto was a key part in an impressive Alto restoration that visitors could use. At CHM itself, the Alto archive proved indispensable to a number of projects, ranging from its own restoration of an Alto, a major event on the history of the Alto, and a series of video ethnographies of software innovations on the Alto.

Charles Simonyi (standing) and Tom Malloy demonstrate the Bravo word processor on a restored Alto for a 2017 Computer History Museum event. Courtesy Doug Fairbairn.
But what of the rest of the PARC archive from the 1970s and 1980s that resided on the sixteen or so DVDs that remained sitting in a box? Could the rest of the archive be collected by CHM and, through it, be released to the public? Did the archive contain sensitive personal information that should not be released? Did it contain intellectual property that was still vital for PARC, or that was owned by others? Could these types of materials be identified and filtered out?
Once again, Paul McJones offered his expertise and help. Acting as a CHM volunteer, he entered into an NDA (non-disclosure agreement) with PARC enabling him to work there on the remaining archive. He copied the archive from the DVDs to a contemporary hard drive and identified personal files that should be filtered out. He used his translation and organization program to make the remaining archive readable and accessible and transferred it to PARC researchers and legal staff for review. Eventually it was sent to CHM. The resulting archive of nearly one hundred fifty thousand unique files of PARC’s groundbreaking work from the 1970s and 1980s arrived at CHM on a thumb drive and could now be made available to the public.

A screenshot of a Press file, detailing PARC backup procedures, now rendered as PDF in the new archive.
With the new archive, new challenges arose in preparing it for public release. Paul McJones’ program could convert Press and Bravo files to PDF and HTML, making them readable, but not the Tioga files found in great abundance in the new archive. Tioga is the file format for a successor text editor to Bravo that the PARC researchers had created and used extensively in the 1980s. A significant fraction of the archive remained inscrutable. This time, Josh Dersch, the creator of the Alto emulator, answered the call. He was able to supply logic for Paul McJones’ program to render Tioga files as HTML documents. The archive was finally unlocked.
The nearly one hundred and fifty thousand unique files —around four gigabytes of information—in the archive cover an astonishing landscape: programming languages; graphics; printing and typography; mathematics; networking; databases; file systems; electronic mail; servers; voice; artificial intelligence; hardware design; integrated circuit design tools and simulators; and additions to the Alto archive. All of this is open for you to explore today at https://info.computerhistory.org/xerox-parc-archive Explore!
One thing that is missing, hopefully temporarily, are files related to the critically significant programming language and environment Smalltalk. Smalltalk is a key piece in both the history of object-oriented programming and that of the graphical user interface. The Smalltalk materials in the archive are currently under review by the company Cincom, which owns significant intellectual property rights in Smalltalk and markets Smalltalk-based software globally today. An additional unresolved question is what 8mm tape backups may possibly remain at PARC for the NFS servers, holding the archives of work done at PARC across the 1990s and in the new millennium. It is a topic for further investigation.
What kinds of discoveries await in https://info.computerhistory.org/xerox-parc-archive? I'd like to share something really surprising and fascinating that I came across in the archive—a new story that has enriched my view of a topic in the history of computing that is tremendously important. I hope that it might inspire you to find your own discoveries in the archive.
Take a moment to consider how most writing occurs today. What tools do people most commonly use? Pencil and paper? Pen or brush and ink? Compare that to all the writing that we do through computing: taps on a keyboard—physical or onscreen—assembling texts, messages, posts, mail, lists, and documents of a bewildering assortment. Think also of voice to text, itself a kind of writing, sending messages, submitting search queries, and the like. In many parts of the world today, I think it’s very safe to say that most writing takes place through computing. How did this happen? One thing is certain, it did not happen on its own. How did we make computers write? This question animates my new book project, and while it is at an early stage one finding is absolutely clear: Many of the most innovative minds in the history of computing have devoted an extraordinary amount of time and energy to this very project of making computers write.
One of the episodes in this long historical project is the creation of PostScript, a coding language that afforded the ability for computers to produce high-quality printed pages. It acted as a common language that let you print exactly what you wanted, no matter which computer, app, or printer you happened to be using. I wrote about the story of PostScript a few months ago, when CHM released the source code for PostScript in connection with the fortieth anniversary of Adobe, the company that made it. While you may not be familiar with PostScript, you are certainly intimately aware of a technology that directly developed out of it: PDF.

Adobe cofounders John Warnock (left) and Chuck Geschke (right). Courtesy Adobe Inc. and Doug Menuez.
Adobe was founded in 1982 by two Xerox PARC computer researchers, Chuck Geschke and John Warnock, and their first order of business was to create PostScript. The reason was that the pair had worked with others—Butler Lampson, Bob Sproull, and Brian Reid—on a very similar project at PARC, the coding language Interpress. While Interpress differed from PostScript in some aspects of fundamental approach, the intention behind Interpress was exactly the same: creating a coding language for the high-quality printing of documents. Computers, programs, and printers that could “speak” Interpress would be able to cooperate seamlessly. The Interpress effort had started in Geschke’s laboratory at PARC in 1979, and by 1981 it had reached an advanced state of development. Leadership at Xerox had even agreed that Interpress would become the whole corporation’s standard, but that this would take years to happen. Concerned about that slow pace in the face of rapid developments in computing, Geschke and Warnock left PARC in 1982, forming Adobe to get a standard coding language for printing quickly into the world.
What I stumbled across in https://info.computerhistory.org/xerox-parc-archive reveals part of the story of what happened next for the researchers who had worked on Interpress and who remained at PARC. This was a new effort, initially called InterDoc, later Interscript, that aimed to do for editable documents just what Interpress and PostScript did for printable documents. Perhaps the same approach—creating a new coding language for the interchange of documents between various computers and apps—could work here as well.
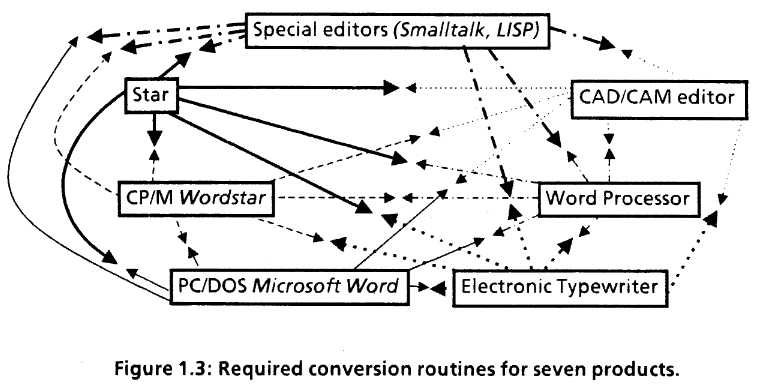
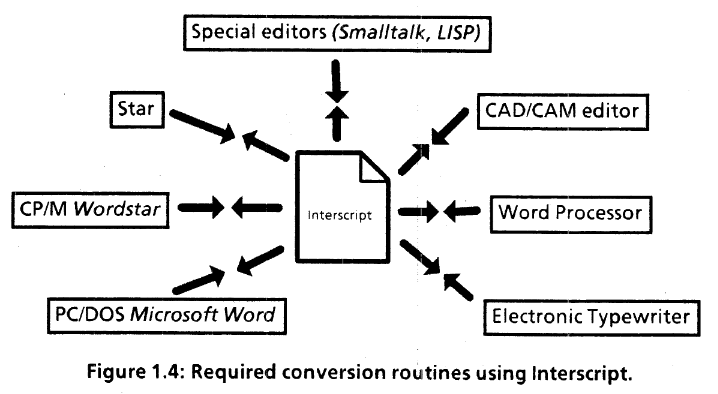
The promise of Interscript, in two figures from a 1985 Xerox document. https://bitsavers.org/pdf/xerox/interscript/IntroductionToInterscript.pdf
The Interscript effort, as electronic mail held in the archive show, really took off in 1981 as the success of Interpress became clear. Spurred by Butler Lampson and Jim Mitchell, the project also included Brian Reid, who had worked with Lampson on Interpress, as well as Bob Ayers and Jim Horning, who worked especially closely with Mitchell. The Interscript project ran from 1981 into at least early 1984.

An email exchange in the archive, documenting the emergence of the first name for the effort, InterDoc.
What the Interscript team immediately discovered was that editable documents presented a greater challenge than printable documents. Editable documents were inherently dynamic. By definition, they were going to be subject to constant change. And these changes were not just about what words they contained and in what order. These changes were also about the organization and appearance of the text, the layout, from outlined or numbered text to headlines, captions, illustrations, columns, and the like. Creating a coding language that could contend with such dynamic complexity was a true challenge.
Furthermore, the editors that were emerging in the first half of the 1980s ran from the rudimentary to the elaborate. This spread of editor functions was itself another challenge. How could an interchange format work from the simplest to most complex editors? How could simple editors just work on the parts of a document that they could, but leave everything else alone?
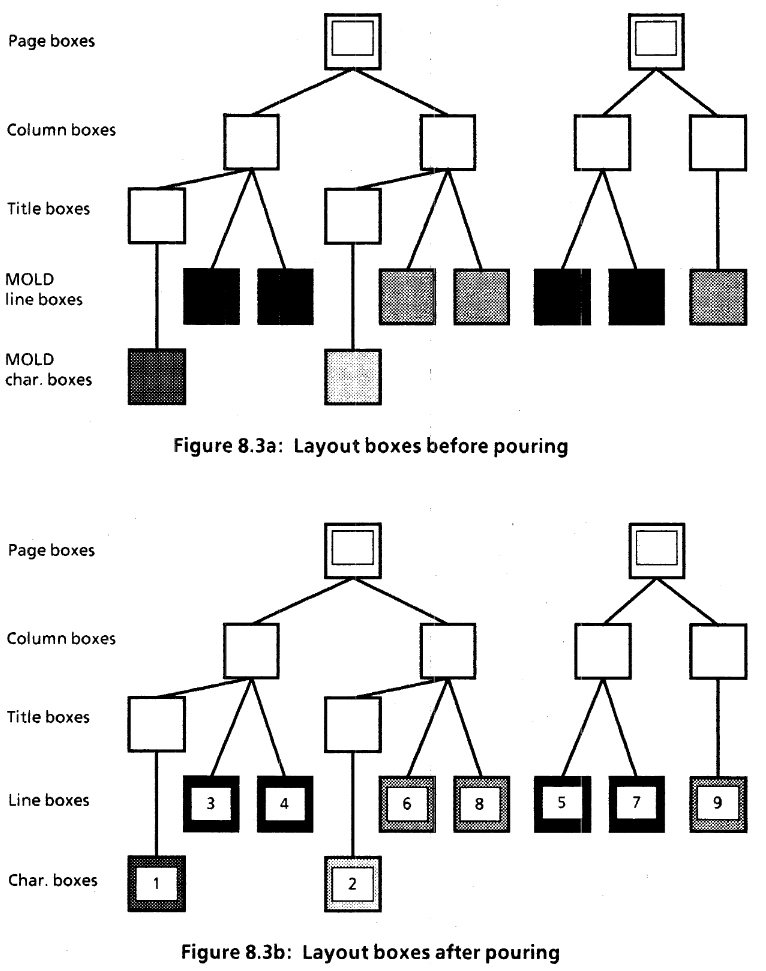
The tree structure of Interscript’s layout templates. https://bitsavers.org/pdf/xerox/interscript/IntroductionToInterscript.pdf
To meet the challenges, the Interscript team again turned to computer science. Not only would they turn to a new coding language as part of the solution, but they would also look to one of the key organizational forms of computer science, the “tree” data structure. In it, elements are connected to one another in a hierarchy, just like the trunk of a tree leads to branches, and on to sticks and then twigs, each step in greater profusion. Very roughly put, Interscript would capture the possible layouts of an editable document as a tree structure of possible templates. Careful control algorithms would then guide the “pouring” of the text into the proper templates of the tree. These scripts would allow the editable document to be reconstituted, edited, and then shared between different computers and programs.

A portion of a November 1983 Tioga document, rendered as HTML in the archive, summarizing some of the milestones and motivations of the Interscript project.
Although significant progress had been made on designing Interscript into early 1984, the effort then appears to have ended abruptly. While Butler Lampson, in a telephone interview with me recently, holds it ultimately ended because it was “naïve” given the complexity of editable documents, another factor was that, at the end of 1983, the Computer Science Laboratory at PARC descended into chaos. This was the Laboratory that housed the Interscript project, and its charismatic leader Bob Taylor abruptly resigned, soon followed by half of its technical staff. Lampson left to rejoin Taylor, and Mitchell, temporarily thrust into the position of the manager for the unravelling laboratory, himself quickly departed for Acorn Computers.
Remarkably, Lampson explains, no one has yet to solve the problem that Interscript set out to address. We still lack a common format for editable documents that can contend with layout well. In his view, only partial and de facto solutions exist. Microsoft’s Word, itself originally directly based on the Bravo editor from Xerox PARC, has become a de facto standard, but only because any editor needs to work with Word documents if it is to be commercially viable. And even so, we all know how layout suffers when moving a document from one editor to another. PDF, with its roots in printed documents, only succeeds in limited ways with editing. For his part, Mitchell believes that the fundamental approaches of Interscript had great promise, and that if they had been more diligently pursued by PARC and Xerox, our lives with electronic documents could have been much different, and for the better.
So here, in a single, small directory in https://xeroxparcarchive.computerhistory.org, lies a fascinating story about making computers write, and an unsolved problem within it. Who knows, perhaps the person who finally solves it will find inspiration in the archive.
This archival project, and this article, would have been impossible without the efforts of:
Al Kossow
Paul McJones
Hansen Hsu
Josh Dersch
Butler Lampson
Jim Mitchell
Tim Curley
Heather Walker
Eric Bier
John Kitchura
PARC, A Xerox Company
Xerox
James K. Foote, author of the 1991 README in the rosetta.tar file of the PARC archive, and who accomplished the transfer of the 9-track MAXC tapes to 8mm tapes.
David C. Brock, “50 Years Later, We’re Still Living in the Xerox Alto’s World,” https://spectrum.ieee.org/xerox-alto
The Alto in CHM’s flagship exhibition, Revolution: The First 2000 Years of Computing, https://www.computerhistory.org/revolution/input-output/14/347
A selection of video recordings featuring an Alto computer restored by CHM, https://youtube.com/playlist?list=PLQsxaNhYv8dbSX7IyztvLjML_lgB1C_Bb
A 1986 lecture by Alan Kay, “The Dynabook—Past, Present, and Future,” https://www.youtube.com/watch?v=GMDphyKrAE8&list=PLQsxaNhYv8dbIuONzZcrM0IM7sTPQFqgr&index=8
A 1986 lecture by Butler Lampson, “Personal Distributed Computing – The Alto and Ethernet Software,” https://www.youtube.com/watch?v=h33A-KWJKDQ&list=PLQsxaNhYv8dbIuONzZcrM0IM7sTPQFqgr&index=9
A 1986 lecture by Chuck Thacker, “Personal Distributed Computing – The Alto and Ethernet Hardware,” https://www.youtube.com/watch?v=A9n2J24Jg2Y&list=PLQsxaNhYv8dbIuONzZcrM0IM7sTPQFqgr&index=10
Blogs like these would not be possible without the generous support of people like you who care deeply about decoding technology. Please consider making a donation.