
Editor's Note: This blog is a companion to AI and Play, Part 2: Go and Deep Learning.
"But What Is a Neural Nework?" Video: Courtesy Grant Sanderson, 3Blue1Brown.
As the name suggests, artificial neural networks are modeled on biological neural networks in the brain. The brain is made up of cells called neurons, which send signals to each other through connections known as synapses. Neurons transmit electrical signals to other neurons based on the signals they themselves receive from other neurons. An artificial neuron simulates how a biological neuron behaves by adding together the values of the inputs it receives. If this is above some threshold, it sends its own signal to its output, which is then received by other neurons. However, a neuron doesn’t have to treat each of its inputs with equal weight. Each of its inputs can be adjusted by multiplying it by some weighting factor. Say, if input A were twice as important as input B, then input A would have a weight of 2. Weights can also be negative, if the value of that input is unimportant.
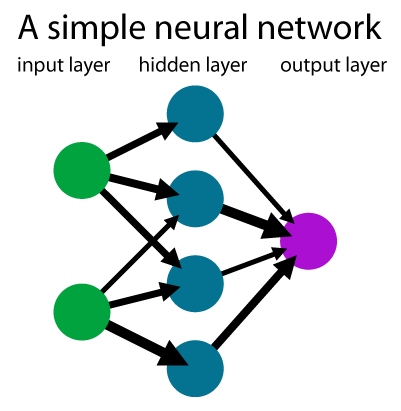
Diagram of a simple feed-forward artificial neural network, with one “hidden layer,” also known as a “perceptron.” Image: Wikipedia.
Each neuron is thus connected to other neurons in the network through these synaptic connections, whose values are weighted, and the signals propagating through the network are strengthened or dampened by these weight values. The process of training involves adjusting these weight values so that the final output of the network gives you the right answer.
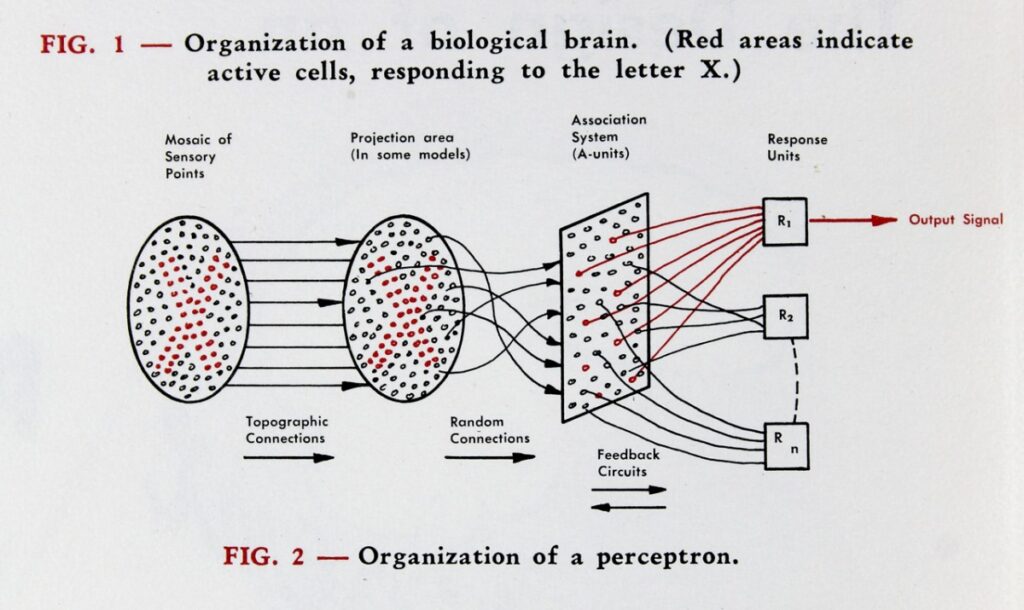
Diagram of a perceptron, from Frank Rosenblatt’s “The Design of an Intelligent Automaton,” published by the Cornell Aeronautical Laboratory, 1958. The “Association System” corresponds to a single “hidden layer” in modern neural networks. Image: Cornell University Library, Division of Rare and Manuscript Collections.
The simplest version of an artificial neural network, based on Rosenblatt’s perceptron, has three layers of neurons. The first is the input layer. This takes input values–say, the pixels of a photograph. The outputs of this first layer of neurons are connected to a middle layer, called the “hidden” layer. The outputs of these “hidden” neurons are then connected to the final output layer. This final layer is what gives you the answer to what the network has been trained to do. For example, a network can be trained to recognize photos of cats. The output layer of the network would then have two outputs, “cat” or “not cat.” Given a dataset of photos which a human has labeled with either “cat” or “not cat,” the network is trained by adjusting its weights so that when it sees a new unlabeled cat photo, it outputs a greater than 90 percent probability that it is a cat, or less than 10 percent if it is not. Neural networks can classify things into more than two categories as well, for example handwritten characters 0-9 or the 26 letters of the alphabet. Perceptrons were limited by having only a single middle “hidden” layer of neurons. Although Rosenblatt knew having more inner hidden layers would be helpful, he did not find a way to train such a network. It wasn’t until connectionists in the 1980s, like Geoffrey Hinton, applied the algorithm known as “backpropagation” to training networks with multiple hidden layers, that this problem was solved. Networks with many hidden layers are also known as “multilayer perceptrons” or as “deep” neural networks, hence the term “deep” learning. How many layers and how many neurons an artificial neural network should have is known as its “architecture,” and figuring out the best one for a particular problem is currently a process of trial and error and closer to an art than a science. Ironically at the very heart of today’s neural network design lies a big space for human ingenuity.
The example above used a labeled dataset to determine whether a picture was a cat or not. Training with such human-labeled data constitutes what is called “supervised” learning, because it is supervised by human labels. Much of today’s deep learning systems are powered by such supervised systems, and it is here that human biases in the pre-labeled data can bias the network too. There are two other kinds of machine learning. Unsupervised learning simply gives the network unlabeled data, and asks it to try to find patterns and clusters of similarity in items on its own, and humans come in after the fact to give some names to the clusters the network has found. Unsupervised learning can be combined with supervised learning to pre-train a network that is then trained with labeled data, greatly reducing training time with supervised learning alone. A third type of machine learning is called reinforcement learning. Reinforcement learning is generally used in games. Instead of being given external data of winning and losing games, the system generates this data by playing itself over and over again, getting better each time. Reinforcement learning was inspired by ideas of how children learn to do good things through rewards and avoid doing bad things via punishments. DeepMind used a combination of supervised and reinforcement learning to create AlphaGo.