

CHM Live’s “Engineering Emotional Intelligence: Affectiva CEO Rana el Kaliouby in Conversation with Museum CEO John Hollar,” June 8, 2017.
What could your computer or phone do if it knew what you were thinking? Are men or women more expressive? Do cultures express their emotions differently? And what is the Mona Lisa thinking already? Affectiva knows.
Dr. Rana el Kaliouby and her team at Affectiva are pioneering an aspect of AI that augments human intelligence with sophisticated imagery to quantify emotion in real time. At 4.8 million faces throughout 75 countries, Affectiva has amassed the world’s largest emotion recognition database used by content creators, market researchers, advertising agencies, and companies, including CBS, Kellogg, and Mars, with goals to expand into healthcare and transportation. The company, spun out of MIT’s Media Lab, has processed over one billion frames of video to produce more than 50 billion data points of human emotion. Affectiva’s technology can be downloaded to any device and used within the comfort of your home.
On June 8, Affeciva co-founder and CEO Rana el Kaliouby joined the Museum’s John Hollar for an enlightening conversation about the emotion-sensing technology that is defining the world’s emotional intelligence.
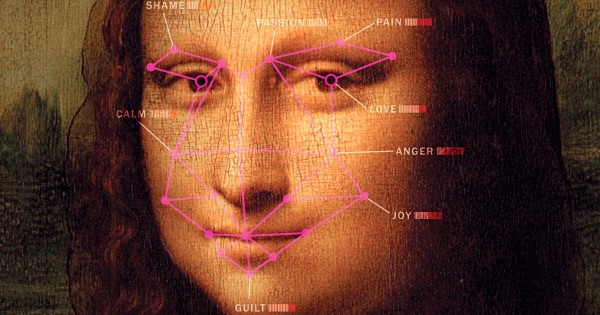
Have you ever wondered what the Mona Lisa was thinking? So did Affectiva. Watch the full show to discover what they concluded.
Kaliouby recalls the first research presentation she gave at Cambridge. She began with her back toward the audience, an intentional gesture to underscore that facial expressions are an essential part of how we communicate and how we connect with each other. During this same talk, an audience member stood up and simply concluded that what Kaliouby was actually doing was teaching computers how to read emotions; he then shared that his brother was autistic and that she should consider how her research might be applied in the autistic community. The moment was profound for Kaliouby and she came to the realization that “we’re building technology that’s not just going to make computers better; it actually has the potential to help humans communicate better.”
She quickly connected with Cambridge’s autism research center, which at the time was building an emotional repository to teach kids with autism how to read and communicate emotions. The repository had examples of people expressing over 400 different vocal and facial expressions. She then wondered if she could use those same datasets to train her algorithms.
Hear how Dr. Rana el Kaliouby is creating an emotional hearing aid to help those with autism recognize and understand emotions to communicate better their own emotions...
Hollar asked Kaliouby about the taxonomy and classification of facial muscles to gain a better understanding of the history of emotional coding. Humans have roughly 45 facial muscles that drive thousands of combinations of expressions, she explained to the audience. In 1978, Dr. Paul Ekman and his team developed the Facial Action Coding System (FACS), the definitive coding system to map every facial muscle to an expression. To become a certified FACS coder, one had to undergo 100 hours of training. It took five minutes to code one minute of video. Kaliouby and her team took this concept, but used machine learning to automate the coding process.
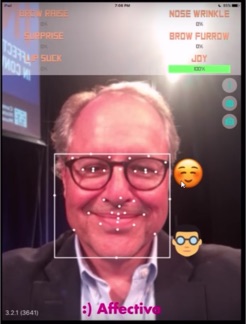
Museum CEO John Hollar demos Affectiva technology.
Kaliouby then invited Hollar to demo Affictiva’s software: “Let’s see how expressive you are.” As Hollar demoed the technology, expressing various emotions (“surprise” being his favorite), he asked Kaliouby about the white dots speckling his face on the screen. She explained that Affectiva’s technology uses computer vision machine learning, first locating your face on the screen before triangulating the main feature points on your face (for example, your eyebrows, mouth, eyes, lips, etc.). This helps the algorithms align a user’s facial information. It then analyzes each pixel on your face for texture changes and color combinations, which is what it uses to determine your expression.
Have you ever wondered what someone’s facial expressions mean? Watch the Museum’s John Hollar demo Affectiva’s emotion recognition technology in front of a live audience...
While her software is rapidly transforming the advertising industry, Kaliouby continues to be intrigued by the possibilities of applying this technology to mental health, in particular to treat anxiety and depression. Some research, she says, shows that tone of voice as well as facial expressions can be early markers for depression in some patients. Kaliouby offers that emotion-sensing technology could be a powerful tool for monitoring behavioral changes in patients and could call for help or flag the change to a clinician or relative. Technology could also help diagnose patients and even evaluate the effectiveness of treatment in real time rather than relying solely on self-reporting. The technological potential is great, but Kaliouby notes that her company needs to collect more data in order to build predictive models to accurately identify behavioral baselines.
What if a smart device could detect depression or recognize signs of other mental illness by studying your facial expressions? It may be what’s next for Affectiva’s emotion recognition software. ..
“We see a world, where in three to five years down the line, all of our devices are going to have an emotion chip that can respond to your emotions,” Kaliouby asserted. This includes our cars.
The trend is toward conversational interfaces, Kaliouby shared. “Eventually, all cars will be autonomous. But there will be a number of years where it’s semiautonomous, and the car needs to relinquish control, at some point and time, back to the driver. But it needs to know if the driver is paying attention or not, is she or he awake, are they watching a movie, are they texting. And so understanding the mental state of the driver is becoming really critical.” That’s the safety aspect.
Then, she says, there’s the idea of the car becoming more of a concierge that can personalize your driving experience, from changing the lighting to the music. Technology will be able to collect and learn your preferences based on your facial expressions and your tone of voice and will eventually be able to initiate a conversation with you based on what its learned about you. Interfaces will become relational rather than transactional. According to Kaliouby, we won’t be saying “Hey Siri” or “Alexa” forever.
IHow does Affectiva’s Dr. Rana el Kaliouby envision her company’s emotion recognition technology being used in cars?..
Affectiva’s technology is only in the beginning phases. Kaliouby likens it to a toddler. It can register the basic emotions, but there is still much to learn in the realm of emotions, including nuanced and complex emotions like inspiration or jealousy.
Combining multiple modalities, including gestures and tone of voice, to understand people’s true emotional internet is what’s next for Affectiva. Kaliouby says, “Only 10 percent [of how you feel] comes from the words you’re actually saying; 30 to 35 percent is in how you’re saying those words; and the rest is facial expressions and gestures.”
While Affectiva is at the forefront of recognizing our facial expressions, there’s still more to understanding a person’s emotional intent. Analyzing a person’s tone and gestures may be the next frontier for the company according to its CEO, Dr. Rana el Kaliouby...
CHM Live’s “Engineering Emotional Intelligence: Affectiva CEO Rana el Kaliouby in Conversation with Museum CEO John Hollar,” June 8, 2017...