
Across the generations, people have dreamed of speaking to machines or spirits to gain knowledge or carry out tasks and commands. In the ancient folk tale of Ali Baba and the Forty Thieves, the door to the cave of hidden loot is opened by uttering the phrase, “Open Sesame!”—making it possibly the world’s earliest voice-activated device! In the twentieth century, science fiction authors in particular have written about machines and sentient beings that could understand and react to human speech. Their visions of the future often assumed that one day we would interact with our machines by speaking to them. To look at two examples, the classic television show Star Trek, which shaped the ambitions and hopes of generations of budding engineers and scientists, often featured the voice of the main ship’s computer fluidly interacting with the crew. The voice of the computer itself, by the way, was voiced by Majel Roddenberry, wife of Gene Roddenberry, the show’s creator.
Here’s a typical clip from Star Trek showing the voice interface on-board the USS Enterprise:
Star Trek: The Original Series, Season 1, Episode 13: “The Conscience of the King."
Another epic futuristic vision of human-computer interaction via speech was the HAL 9000 computer system in Stanley Kubrick’s film 2001: A Space Odyssey. “HAL,” as he is known to the crew, is considered another crew member, but one whose duties involve every aspect of ship operations. He was voiced by Canadian stage actor Douglas Rain, whose rendition of HAL was far from the existing often cartoonish portrayals of computers speaking with "robotic" voices. As HAL managed the Discovery-1 spaceship, his only means of expression was his voice, and it is what makes him almost human in the story—Rain’s subtle inflections seem to express unspoken emotions, something that we thought computers didn’t do. As HAL loses his digital mind in the movie, he reverts to what can only be described as a "childhood" memory—that of a song taught to him by Mr. Langley at the HAL Labs when he was being manufactured.
Deactivation of the HAL 9000 computer. Stanley Kubrick, 2001: A Space Odyssey, 1969.
One of the weird things about predicting the future is how uneven our predictions can be. The Star Trek story, for example, nominally takes place in the 23rd century and posits many advanced technologies, yet its crew are still using clipboards and have no seatbelts. As we saw earlier, however, they did get speech recognition right. How did this science fiction fantasy of only a few decades ago come true?
The quick answer is that it’s a long answer, but one that we’ll keep brief for this blog. In essence, behind the "magic" of speech recognition, lies generations of researchers contributing to decades of slow, continuous progress; copious government funding; and great leadership.
Speech is a highly complex varying signal comprising many parameters. Who, where, how, and what people are saying can combine in nearly infinite ways. Some of these parameters are shown in the image below. Progress in speech recognition typically has occurred along different dimensions at different rates.
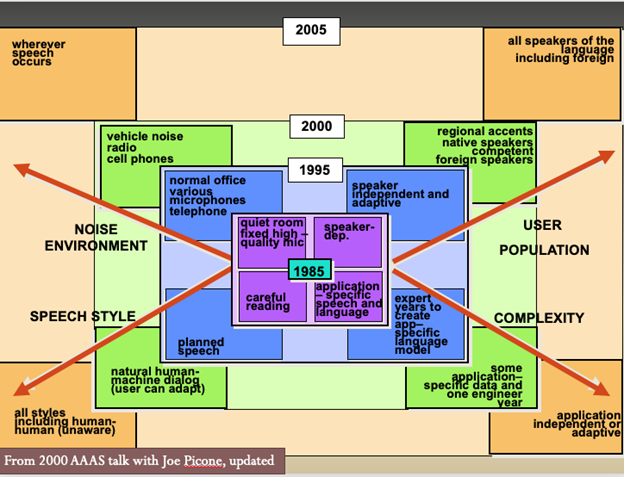
The multiple dimensions of speech recognition. Courtesy Patti Price, 2021
There have been three main eras in the development of speech recognition: a) an early period using either systems that matched speech against recorded templates, or ones that supplied linguistic knowledge to rule-based AI systems; b) a statistically-driven period in which probabilities (rather than absolute rules) were used to estimate the likelihood of a match of strings of words; and c) the current period in which deep neural networks, giant datasets, and cloud based servers and storage provide near real-time speech recognition between these systems and mobile devices.
Let’s take a whirlwind tour of speech recognition’s early history, including how the problem was (mostly) solved, and where we are today.
We start our story in 1952 at Bell Laboratories. It’s a modest start: The machine, known as AUDREY—the Automatic Digit Recognizer—can recognize the digits zero to nine, with 90% accuracy, but only if spoken by its inventor. Yet even that is impressive for its time.

1952 Bell Labs Audrey. Not shown is six foot high rack of supporting electronics.
IBM followed suit ten years later with its "Shoebox" recognizer, which did much the same thing. In fact, throughout the 1950s and '60s, speech recognizers of similar types were being made around the world in various laboratories, including University College London, RCA and NEC in Japan.

Inventor William Dersch shown in photo, 1961.
One of the early innovators of that era was Raj Reddy, then a graduate student from India pursuing his studies at Stanford University under artificial intelligence pioneer John McCarthy. Using the special DEC PDP-1 computer with an attached analog-to-digital converter, Reddy began building his PhD project, a vowel recognizer. Reddy is the first to research the problem of continuous speech recognition, in which speakers do not need to pause between each word.
In these early days of speech recognition, there are two competing approaches. In one, words are recognized by comparing new utterances against prerecorded template waveforms, and dynamically squishing or stretching them to match talking speeds. In the other, different levels of linguistic knowledge in the form of complex rules are used to make guesses about what an utterance could be, and the highest-ranking guess is chosen. Defense agency DARPA funded development of speech recognition beginning in 1971 and continuing for the next five years. Their goal was to recognize 1,000 words by 1976. Five institutions, including Carnegie Mellon—where Raj Reddy was now a professor—participated. Such funding was critical for pursuing speech recognition research since this new discipline was a new domain of computing, one with uncertain prospects or likelihood of success.
There were four CMU speech recognition projects funded over this period. Let’s have a quick look at each one and their associated technical milestones. Since speech recognition has multiple factors to worry about, progress in these projects is often along only one or two dimensions at a time.
Hearsay-I was the first moderate vocabulary continuous speech recognition system. It was developed in 1972 by Reddy’s graduate students L.D. Erman, R.B. Neely, and R.D. Fennell and could process general speech, not only narrow task-specific words. The Hearsay system took spoken language as input and produced a typed version of what was said as output. Chess was chosen as a task for the Hearsay system because it has a well-defined syntax, semantics, and vocabulary.
In 1974, James and Janet Baker develop the DRAGON system, using a statistical method known as Hidden Markov Models, instead of traditional rule-based approaches. This allows for large vocabulary continuous speech recognition.
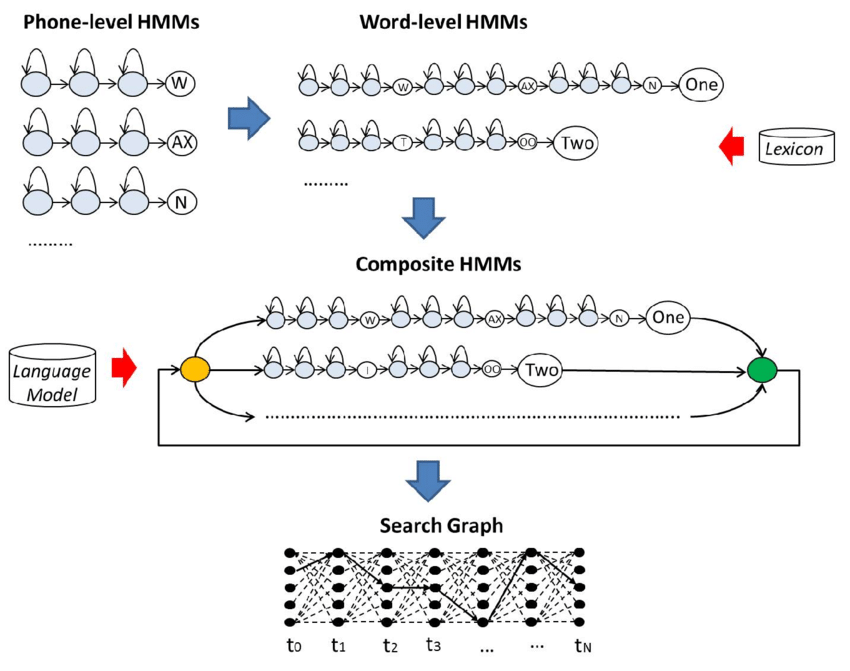
The Bakers’ use of Hidden Markov Models.
We have a winner! Using a new method known as “Beam Search,” HARPY wins the DARPA challenge to recognize 1,000 words by the 1976 deadline. HARPY was written by Reddy graduate student Bruce Lowerre. In Beam Search, to select the best translation, each part of speech is processed and different ways of translating the words appear. The best translations according to their sentence structures are kept, and the rest are discarded.
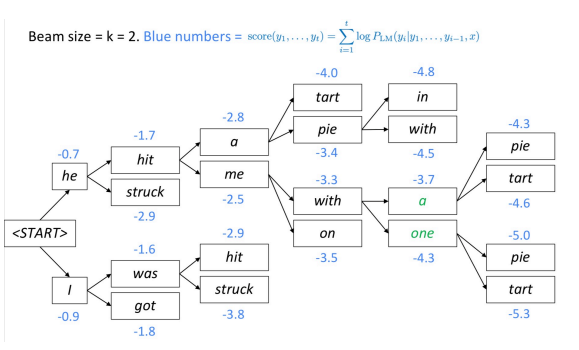
How a beam search constructs and decodes a sentence.
Hearsay-II, which came out last, introduced the "Blackboard" architecture, assigning multiple knowledge sources to work on the recognition problem in parallel. Each of these knowledge sources, ranging from acoustic- phonetic, phonemic, lexical, syntactic, semantic, prosodic, discursive, and even psychological, could independently suggest a better guess of a string of words for the speech signal in question by “writing” it on the virtual blackboard, and other knowledge sources could then improve on those guesses. This new blackboard method of conceiving problem domains diagrammatically has become widely used in AI research generally.
Meanwhile, after working at IBM and Verbex for a few years, former Reddy grad students James and Janet Baker founded Dragon Systems in 1982 to pursue their dream of commercial speech recognition. In 1984, they licensed their software to makers of the Apricot computer, providing the first speech recognition capability for a personal computer.

The ACT Apricot personal computer, with built-in voice recognition.
The Bakers' former colleague Fred Jelinek at IBM led the Tangora project, a voice-activated dictation system meant for office workers. Like the Bakers, it was based on statistical methods and could recognize up to 20,000 words. Tangora showed IBM’s confidence in the statistical approach and began a parallel effort at IBM to develop speech recognition on its own. Interestingly, the system was named after Albert Tangora, an American speed typist who set the world record for sustained typing on a manual keyboard for one hour at 147 words per minute. He did this in 1923, and the record still stands.

IBM speech recognition system developed by Fred Jelinek and others, ca. 1985.
For the sci-fi version of this technology...
Special Agent Gary 7 dictates to a typewriter that can recognize speech.
In 1984, another round of US government funding lead to a second renaissance in speech recognition. Widely available datasets and benchmarks enabled measurement and comparison of different systems, resulting in competition and progress. A significant factor in the progress achieved was that the National Bureau of Standards (now NIST), served as a clearinghouse for researchers trying to benchmark the performance of their code. Using common vocabularies and metrics, great progress was made among the various groups involved: CMU, SRI, BB&N, MIT and Bell Labs.
Raj Reddy graduate student Kai-Fu Lee developed SPHINX-I in 1987, the first speaker-independent continuous speech recognition system. He did so by combining Dragon’s Hidden Markov Models with HARPY’s Beam Search. Now speech systems no longer have to be trained for a specific speaker. This is a major development since the "training" time for speech recognition systems in these early days could be significant. If speech recognition was ever to come to the masses, speaker independence was a must.

Kai-Fu Lee as a CMU graduate student under Professor Raj Reddy.
In 1997 Dragon released Dragon Naturally-Speaking, their first general purpose continuous speech product for consumer PCs. It could recognize 100 words per minute, but required training. Nonetheless, it was a blockbuster product.

Early Dragon: Naturally-Speaking software box.
In the last decade, a third round of DARPA largesse has resulted in more progress. This third round corresponds with a new way of doing things—Deep Neural Networks (DNN). DNNs are now the most widely-used approach for speech recognition. By 2017, DNNs had reached human-level performance, about a 5% error rate, and in the 2010s, a series of voice-enabled applications and devices saturated the market: Alexa, Google Home, Cortana, Siri.
Speech recognition has spread widely into daily life, from helping the disabled write emails, to helping us order that new cat toy on Amazon, to supporting F-16 pilots in flight. Speech recognition does best when limited to a specific domain (like medical or legal transcription). Today’s portable devices are both using and improving speech recognition at the same time. They do this by sending speech data to remote servers for recognition and then sending back the result. These servers then harvest the speech data and its resulting translation into giant training data sets for the speech recognition software to "chew on" and improve itself.
Areas in which the technology still struggles include dealing with accents (national, regional, and sometimes even local) or being truly speaker independent across a wide range of variations. Additionally, of the thousands of human languages in existence, only a handful are represented in speech recognition systems. That will need to change if the dream of all peoples communicating with one another is to become a reality. What's exciting is that today’s systems, because they are based on continuously updated neural networks, are never finished learning. New datasets with new accents, pronunciations, dialects, and meanings are forever being generated, in real-time, by every person using speech recognition systems in a process of mutual alignment and convergence. In this sense, speech recognition systems are as dynamic and creative as human languages are themselves.
Want to learn more about ASR and the people behind the innovations? Join us for Empowering Humanity Through Technology: A Celebration of Raj Reddy.